
Most data modernization programs fail quietly. Not with a dramatic system collapse, but with a slow accumulation of delays. Reports that take too long. Pipelines that break on weekends. Compliance reviews that consume entire quarters.
The data is there. The problem is everything built around it.
Cloud data modernization addresses exactly that, the architecture, pipelines, governance, and operations that determine whether your data is actually usable or just expensively stored. This guide covers the strategies that work, why sequencing matters more than tooling choices, and how the approach shifts depending on where your organization sits today.
Why “Moving to the Cloud” Isn’t the Same Thing
A lot of organizations have already done the lift-and-shift. They moved their databases to AWS, Azure, or GCP, and discovered six months later that their problems came along for the ride.
Slow queries? Still slow. Data disagreeing across departments? Still disagreeing. Governance? Still a spreadsheet someone updates before audits.
Here’s the distinction that actually matters in planning:
- Migration relocates data. It’s an infrastructure project with a completion date.
- Data modernization changes how data is managed, processed, and trusted across the entire organization.
Data modernization in cloud environments goes further still, it means re-architecting around cloud-native capabilities: elastic compute, managed services, automated governance, and real-time processing that on-premise infrastructure simply can’t replicate. Conflating these three things is where most programs go sideways before they even start.
The Warning Signs Worth Taking Seriously
There’s no single threshold that tells you data modernization is overdue. But certain patterns repeat across organizations that have waited too long:
→ Analytics teams building workarounds because the data they need lives across three systems that don’t talk to each other.
→ Finance and operations producing reports from the same underlying data, with numbers that don’t match.
→ Engineering spending more time keeping pipelines alive than building anything new.
→ A compliance audit, GDPR, HIPAA, CCPA, that requires weeks of manual documentation to pass.
These aren’t edge cases. They’re the ordinary friction of legacy infrastructure, and they compound. Each quarter without modernization is another quarter of decisions made on slower, less reliable information.
The Six Capabilities That Actually Constitute Modernization
1. Cloud Data Architecture: Getting the Foundation Right
Before migration work begins, someone needs to make hard architectural decisions. Which hyperscaler, or combination of hyperscalers. How to handle data that can’t leave certain jurisdictions. Whether a lakehouse model fits the analytical workload better than a traditional warehouse.
Cloud data center modernization sits at the core of this phase, replacing aging on-premise infrastructure with cloud-native platforms on Azure, AWS, or GCP that are designed for today’s data volumes and tomorrow’s AI workloads. This includes storage architecture, compute separation, network design, and disaster recovery, not just database migration.
One thing that consistently gets underweighted in early planning: Infrastructure as Code using Terraform or CloudFormation. Environments that were hand-configured become impossible to replicate consistently, slowing down every downstream team.
The organizations that handle this well share one habit, they build a structured data platform modernization plan before making platform commitments, not after.
Your data infrastructure has the warning signs.
Get a structured data platform modernization assessment, mapped to your actual systems, not a generic checklist.
2. Data Pipeline Development, The Operational Core
Pipelines are where data modernization either delivers or disappoints.
Legacy ETL jobs built for overnight batch windows weren’t designed for real-time analytics or AI feature engineering. ETL migration to cloud isn’t just a technical port of the old job, it’s an architectural rethink of how data moves, transforms, and lands, with orchestration, dependency management, and error handling built in from day one rather than patched in after the first failure.
What modern pipeline architecture actually covers:
- ELT development designed around actual business data flows, not inherited batch logic
- Orchestration with real dependency management, not fragile time-based scheduling
- Incremental processing that handles late-arriving data without full reloads
- API connectivity pulling from the SaaS platforms and operational systems where business data lives
One decision that trips up mid-market teams in particular: tool selection happens before architecture is defined. The right ETL tool for cloud data migration depends entirely on the complexity of your transformation logic, your orchestration requirements, and your Snowflake or warehouse optimization needs, not on what’s easiest to spin up quickly. Teams that pick the tool first and architect around it almost always re-platform within 12 months.
The measure of a well-built pipeline isn’t throughput. It’s how the team finds out when something goes wrong, ideally automatically, before a downstream user notices.
3. Real-Time Streaming: For When Batch Isn’t Enough
Not every use case needs streaming. But for the ones that do, batch pipelines are fundamentally the wrong tool, and no amount of optimization fixes the architecture mismatch.
The use cases that genuinely need sub-second latency: fraud detection, inventory monitoring, IoT telemetry from manufacturing equipment, customer behavior signals feeding personalization engines.
The infrastructure that supports them: Kafka-based stream processing for high-velocity event data at scale. Azure Event Hubs and Microsoft Fabric RTI for organizations on Microsoft’s stack. Complex event processing (CEP) to detect patterns across event streams and trigger automated responses. Edge analytics for distributed operations where routing everything to a central cloud introduces unacceptable latency.
The architectural question isn’t “should we do real-time?” It’s “which workloads need it, and what’s the right infrastructure for those specifically?”
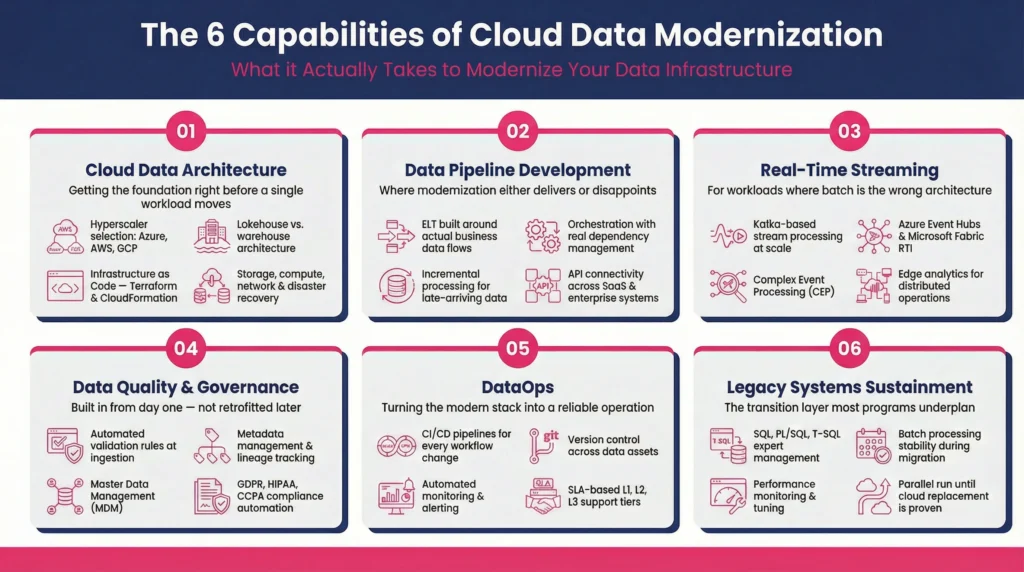
4. Data Quality and Governance: Built In, Not Bolted On
This is the section most organizations skim, and then revisit painfully twelve months later.
Governance retrofitted after a cloud data modernization program is complete costs significantly more and works significantly worse than governance designed in from the start. It’s one of the most consistent findings across modernization programs. It’s also one of the most ignored.
What “built in” actually looks like across a modernized data estate:
| Capability | What it does |
| Automated data quality | Validation rules at ingestion, catches issues before they propagate downstream |
| Metadata management & lineage | Full visibility into where data originates and how it transforms across systems |
| Master Data Management (MDM) | Single trusted version of customers, products, suppliers, across every system |
| Compliance tracking | Automates GDPR, HIPAA, CCPA controls so audits don’t require manual scrambling |
| Data stewardship workflows | Business users can discover, understand, and actually trust what they’re querying |
For financial services, healthcare, insurance, and life sciences, this isn’t optional. It’s the baseline requirement for operating in regulated environments
5. DataOps: Making the Modern Stack Operational
A modernized platform that requires constant manual intervention has traded one set of problems for another. DataOps applies the same engineering discipline to data pipelines that software teams apply to application code.
In concrete terms:
- CI/CD pipelines so every change to a data workflow is tested before it hits production
- Version control across transformations and data assets
- Automated monitoring with alerting that surfaces problems before users do
- SLA-based L1, L2, L3 support tiers matched to the business criticality of each pipeline
The teams that implement DataOps consistently describe the same outcome: data engineers stop spending their days firefighting. That shift in where engineering time actually goes is often the most tangible early return on the entire data modernization investment.
6. Legacy Systems Sustainment: The Part Nobody Loves Talking About
Here’s the reality most modernization plans underplan for: the gap between the target architecture and the production environment is almost always filled with systems that can’t be retired yet.
Mission-critical workloads on relational databases. ETL jobs processing transactions that can’t be interrupted. Reporting infrastructure that half the business depends on daily.
These need serious management throughout the transition, SQL, PL/SQL, T-SQL expertise, performance monitoring and tuning, batch processing stability, running in parallel with the cloud-native buildout. Organizations that treat legacy sustainment as a serious discipline have measurably smoother data modernization in cloud transitions than those that treat it as a distraction from the “real” work.
How the Approach Differs by Organization Size
SMBs get into trouble replicating enterprise architecture patterns they don’t need yet. A two-person data team running a full lakehouse with a complete DataOps toolchain ends up spending all available capacity on maintenance overhead. Managed cloud services exist specifically to abstract that complexity, use them, and focus on core pipeline automation and data quality fundamentals first.
Mid-market organizations tend to underestimate the governance burden. With enough data to have real quality problems but not enough headcount to manually manage them, automated quality controls and lineage tracking pay off faster here than almost anywhere else. The data platform modernization roadmap for mid-market should prioritize governance earlier than feels necessary, because retrofitting it later is always more expensive.Enterprises are where cloud-native data modernization for large businesses becomes a discipline in itself. The complexity of managing hundreds of data assets across multiple business units, regulated environments, and existing technology investments means parallel workstreams are unavoidable. Legacy sustainment and cloud-native buildout must be coordinated, not siloed, or the modernization program creates as many problems as it solves.
Sequencing the Work
Getting the order right matters more than getting the tools right.
1 → Assessment first Inventory actual data flows (not the documented ones, the real ones), map compliance obligations, identify legacy dependencies. The key elements of a modern data strategy data as a product, unified lakehouse architecture, AI/ML readiness, adaptive governance, should inform the assessment framework before a single platform decision is made. Build the data platform modernization plan around business priorities, not technology preferences.
2 → Architecture before migration Define the target state, establish IaC standards, make hyperscaler decisions based on actual workload requirements. Especially for cloud data center modernization, infrastructure decisions made under time pressure are expensive to undo.
3 → Incremental, not big-bang Run modern pipelines alongside legacy systems. Validate data quality before cutover. Retire legacy components only when replacements are proven stable in production.
4 → Optimization as ongoing work Performance tuning, cost optimization, streaming capability, AI/ML infrastructure, these continue after initial migration. Programs that define “done” as the point of migration consistently underdeliver on business outcomes.
Final Thoughts
Most modernization programs don’t fail because of bad tools. They fail because architecture decisions get rushed, governance gets deferred, and legacy systems don’t get the attention they need during the transition.
CaliberFocus has worked across this entire stack through its data engineering and integration services, cloud architecture on Azure, AWS, and GCP, ETL/ELT pipeline builds, real-time streaming, automated governance, and DataOps implementation with production-grade SLA support. Across SMBs and enterprises, the engagements that go well share the same pattern: assessment before commitment, governance before migration, and modernization treated as an ongoing function rather than a one-time delivery.
If your current data infrastructure is slowing decisions down rather than speeding them up, that’s the right moment to revisit the architecture, not after the next audit or the next pipeline failure.
From Legacy Batch Reports to Real-Time Data
How a 1,200-bed network unified its fragmented data on Microsoft Fabric.
Frequently Asked Questions
Migration moves data to the cloud. Cloud data modernization changes how that data is managed, governed, and used once it’s there. Organizations that only migrate typically inherit the same problems on more expensive infrastructure.
SMBs with cleaner data landscapes: 3–6 months for core pipelines and platform. Mid-market: 6–12 months. Enterprise programs with significant legacy debt: 12–24 months for primary workloads, with modernization continuing beyond that. Timelines slip most often when assessment is skipped or when teams attempt a big-bang cutover instead of phased migration.
Depends on your existing stack, team expertise, and workload mix. Azure fits organizations already in the Microsoft ecosystem. AWS covers the broadest range of managed services. GCP has strong depth in analytics and AI/ML workloads. Multi-cloud is an option but adds operational overhead that needs deliberate management.
Before. Every time. Data quality and governance frameworks retrofitted after migration cost more, take longer, and deliver less than ones embedded into the architecture from the start.