
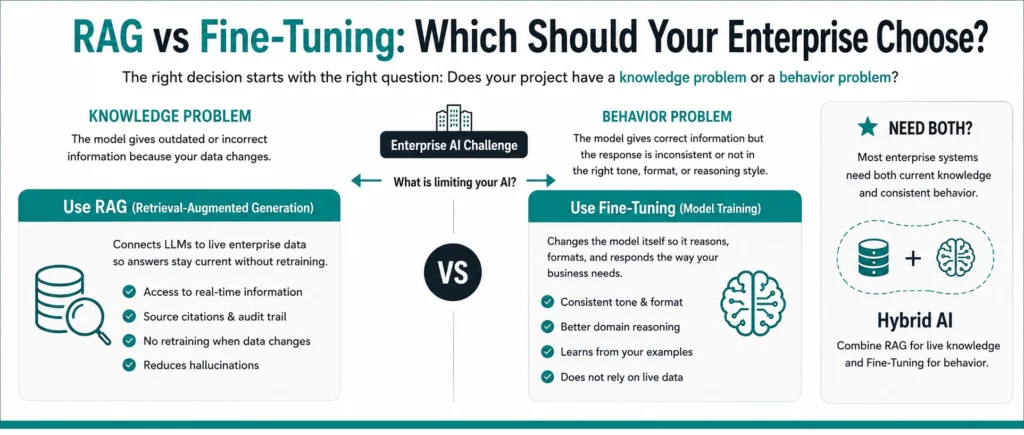
Enterprise AI is not stalling because the models are weak. It is stalling because teams keep answering the wrong question, whether to use RAG or fine tuning, before they answer the question underneath it: does this project have a knowledge problem or a behavior problem.
RAG solves a knowledge problem. It uses retrieval-augmented generation to connect a model with your live enterprise data so answers stay current without retraining. Fine tuning solves a behavior problem. It changes the model itself, how it reasons, formats, and sounds, so output stays consistent without leaning on a live data source. Most RAG vs fine tuning decisions get stuck because someone tries to solve a behavior problem with RAG, or a knowledge problem with fine tuning.
This is not a small bet either. The global RAG market alone is projected to grow past USD 11 billion by 2030 at a 49.1% CAGR (Grand View Research, 2025). Enterprises are not experimenting anymore. They are building for scale.
The Real Difference Is Knowledge vs. Behavior
RAG changes what a model knows. Fine tuning changes how it behaves. Everything else in this decision follows from that split.
Think about what breaks first. If your model gives outdated answers because your policies, prices, or product catalog changed last week, that is a knowledge gap. No amount of retraining fixes it, because the model was never wrong about its training data, it is just missing what happened after training ended. RAG closes that gap by retrieving current information at the moment of the query, instead of baking a snapshot of your data permanently into the model.
If your model gives technically correct answers in the wrong tone, format, or reasoning style, that is a behavior gap. Retrieved documents will not fix it, because the model already has the facts, it just is not using them the way your domain requires. Fine tuning closes that gap through model training on your own examples, adjusting the underlying weights of the foundation model so the large language model reasons the way your business actually needs it to.
Most teams do not lose time picking the wrong tool. They lose time misdiagnosing which gap they actually have.
RAG vs Fine-Tuning at a Glance: Side-By-Side Comparison
Cost, latency, freshness, and governance do not move together. Improving one usually costs you another. That trade-off is the entire decision, laid out plainly below.
Most comparison content treats this as a features checklist, as if the “better” option has more checkmarks. It does not work that way. RAG wins on freshness because it pulls current data at query time, but that same retrieval step is what slows it down and adds ongoing cost. Fine tuning wins on latency and consistency because the model already has everything it needs baked in, but that same trait means it goes stale the moment your policies or data change.
| Factor | RAG | Fine-Tuning |
| Solves | Knowledge gaps | Behavior gaps |
| Data freshness | Real-time, no retraining needed | Fixed at time of training |
| Upfront cost | Lower | Higher |
| Ongoing cost | Scales with query volume | Front-loaded, then stable |
| Latency | Slower (multi-step retrieval) | Faster (direct inference) |
| Best for | Fast-changing knowledge, compliance-heavy answers | Stable domain reasoning, consistent tone or format |
No single row decides the outcome on its own. A team weighing this purely on cost lands on a different answer than a team weighing it on latency or accuracy, which is exactly why the comparison increasingly extends one level further, into RAG vs agentic AI, where the question is not just what the model knows but what it is allowed to act on.
The Myth: “RAG Is Always Cheaper”
RAG’s low upfront cost hides a variable bill that grows with every query, document, and user added. Most enterprises budget for the build and skip the bill that shows up after launch.
Fine tuning charges its full cost once, during training. RAG charges a smaller cost, repeatedly, forever. Every query triggers a retrieval step, every retrieval hits a vector database, and every result adds tokens to the prompt before the model even starts generating a response. At low query volume, that difference is invisible. At enterprise scale, it becomes the line item finance asks about in month four.
USD 1.94B → USD 9.86B
The RAG market is projected to grow from USD 1.94 billion in 2025 to USD 9.86 billion by 2030, a 38.4% CAGR (MarketsandMarkets, 2025), proof enterprises are budgeting for this at scale, not testing it in a sandbox.
This is not an argument against RAG. It is an argument against comparing RAG and fine tuning on sticker price alone. Inference cost for a RAG system scales with usage. Inference cost for a fine-tuned model stays flat once training is paid for. Neither number tells you which one is cheaper for your specific query volume, only which one moves.
What Fine-Tuning Actually Costs Over Time
Fine tuning front-loads its cost once. RAG spreads a smaller cost across every query, forever. That single difference is why the “which is cheaper” question never has a flat answer.
A fine-tuned model’s bill arrives mostly upfront, then goes quiet. Once training completes, inference is direct, there is no retrieval step adding tokens or round trips, and response times stay fast and predictable. That speed comes at a real cost during training itself:
- Compute for the training run, often GPU hours billed by the hour
- Data preparation and labeling before training can even start
- Retraining every time the underlying knowledge changes, not just the behavior
- Evaluation cycles to confirm the retrained model did not regress on existing tasks
The retraining line is where fine-tuning’s economics get expensive fast. A model fine-tuned on last quarter’s compliance language needs a new generative AI and LLM solution rebuilt around that update, and that cost repeats every time the source knowledge shifts, not just once.
Neither approach is the cheap one. Each is cheap for a different pattern of use, and the wrong pattern match is what turns a promising pilot into a budget problem six months in.
Stop Paying to Rebuild the Same Model
We architect LLM solutions that adapt as your data changes.
When Enterprises Should Choose RAG
RAG wins when your knowledge changes faster than any training pipeline can keep up with it. If the right answer today is different from the right answer next month, retraining a model to chase it is the wrong fight.
The clearest signal is data volatility. Pricing, policy, inventory, and compliance language shift on a schedule no fine-tuning cycle can match without becoming a full-time retraining job. RAG sidesteps that entirely by pulling the current version at query time, so the model is always answering off today’s data, not last quarter’s snapshot.
The second signal is citation and audit needs. When an answer has to point back to a specific document, clause, or record, RAG’s retrieval step doubles as a paper trail. Fine tuning cannot produce that, because a fine-tuned model’s knowledge is baked into its weights, not traceable to a source.
RAG is the right fit when:
- Your source data changes weekly or faster
- Answers must cite a specific document, policy, or record
- Labeled training data does not exist or is too costly to build
- Query volume is moderate enough that retrieval cost stays manageable
When Enterprises Should Choose Fine-Tuning
Fine tuning wins when the problem is how the model responds, not what it knows. If your knowledge base is stable but your outputs are inconsistent, wrong in tone, or missing domain fluency, retrieval will not fix that.
The clearest signal is domain-specific AI need. A model answering in clinical, legal, or financial language has to reason like a specialist consistently, across thousands of queries, not just when the right document happens to get retrieved. Fine tuning bakes that fluency into the model itself through deeper natural language processing trained on your domain’s actual vocabulary, so every response carries it by default, not just the ones where retrieval got lucky.
The second signal is query volume paired with knowledge stability. When the underlying facts rarely change but volume is high, retraining once and running fast inference on every query is cheaper and faster than retrieving fresh context on a knowledge base that was not going to change anyway.
Fine tuning is the right fit when:
- Output tone, format, or reasoning style needs to be consistent every time
- The knowledge base is stable and does not need weekly updates
- Query volume is high enough that low latency matters more than freshness
- The task requires deep domain-specific reasoning, not just domain-specific facts
Why Most Enterprise AI Ends Up Hybrid
The real question is not RAG or fine-tuning. It is which layer should own which job. Most enterprise systems that reach production maturity end up running both, not because it is trendy, but because the two problems rarely show up alone.
A single system often needs stable domain reasoning and live data at the same time. A clinical documentation assistant needs to reason like a coder, that is a behavior problem fine tuning solves, while also pulling current payer policy, that is a knowledge problem RAG solves. Picking only one leaves half the system unsolved.
This is also where knowledge management stops being an abstract IT concern and becomes an architecture decision. Structured retrieval keeps institutional knowledge current and searchable, while fine tuning keeps the reasoning layer consistent regardless of which documents got retrieved that day.
| Fine-Tuning Owns | RAG Owns |
| Reasoning style, tone, domain fluency | Live facts, current policy, source citations |
| Behavior that stays consistent every query | Knowledge that changes weekly or faster |
Get RAG and Fine-Tuning Working as One System
If your team is evaluating a RAG deployment for enterprise data, we architect the retrieval layer and the fine-tuning layer together from the first sprint
Frequently Asked Questions
RAG connects a model to your live enterprise data so answers stay current without retraining. Fine tuning changes the model itself, adjusting how it reasons, formats, and responds regardless of what gets retrieved. RAG solves a knowledge problem, fine tuning solves a behavior problem.
Most mature enterprise AI systems run both. Fine tuning handles reasoning style and domain fluency, while RAG supplies live facts and current data at query time, so neither approach has to solve a problem it was never built for.
Fine-tuned models typically respond faster, since direct inference skips the retrieval step entirely. RAG adds a retrieval and ranking pass before generation begins, which is why high-volume, real-time applications often favor fine-tuning when speed matters more than data freshness.
RAG scales well with changing knowledge, but its cost rises with query volume since every query triggers retrieval. Fine tuning scales well with volume once trained, but cannot scale with fast-changing knowledge without repeated retraining runs.
As often as the underlying knowledge changes, not on a fixed schedule. Policies, pricing, or compliance language shifting monthly means a fine-tuned model needs a new training run just as often, unlike RAG which updates automatically at query time.